הקדמה
זוהי סדרה קצרה של מדריכים שיסבירו לכם איך לכתוב קוד שיהיה קצת יותר טוב ויעיל.
הדגש הוא לא על הביצועים, אלא שיהיה קריא יותר, מובן לאחרים וגם לכם, לאחר פרק זמן כלשהו.
המדריכים הם לא ציטוטים של מה שכתוב בספרים, אלא מניסיון של מעל שני עשורים של כתיבת קוד במערכות Embedded, Kernel, ואפליקציות שונות גם בצד השרת וגם בצד הלקוח, בשפות תכנות שונות. גם בתור מפתח בחברות גדולות וסטארטאפים קטנים, וגם אחרי הרבה פרוייקטים בהם אני מפתח לבד.
מדריכים אלה לא מתיימרים ללמד אתכם לתכנת, אלא איך לכתוב את הקוד בצורה שתאפשר ליותר מאדם אחד לעבוד על אותו הפרוייקט, שהקוד יהיה מובן לך וגם לאחרים, יקטין את האפשרויות של באגים וטעויות, ויהיה יעיל וקל לתחזוקה והתפתחות עתידית של הפרוייקט.
ההתייחסות שלי תהיה בעיקר לשפת C/C++, המשמשת בפיתוח לכרטיסי Arduino, אבל כל הפרקים בסדרת מדריכים אלה יהיו רלוונטיים גם לשפות וסביבות פיתוח אחרות.
סגנון כתיבה
נתחיל ממשהו כללי יותר - סגנון הכתיבה. ויש לא מעט כאלה.
אפשר להשוות את זה לצורת הכתיבה בעט, שלכל אחד זה משהו אישי, איך שמתרגלים להחזיק את העט מתקופת בית הספר. אבל בעולם התכנות תצטרכו לפעמים לשנות את ההרגלים האלה כדי להתאים את צורת הקידוד שלכם לקבוצה בה אתם עובדים.
אי אפשר להגיד חד משמעית שבכל שפת תכנות יש סגנון אחיד. מתכנתים בסביבת החלונות לרוב השתמשו בסגנון אחד, שלרוב הוכתב ע"י Microsoft, מתכנתים בסביבות לינוקס השתמשו בסגנון אחר, שגם שם לא היה אחיד, אלא כל קבוצה גדולה קבעה את הסגנון שלה. אלה למשל ההנחיות לכתיבת קוד בקרנל של לינוקס. אלה למשל ההנחיות לכתיבת קוד בספריית ffmpeg המטפלת בקידוד וידאו, שתיהן ידועות בקשיחות של המפתחים להיצמד להנחיות הסגנון.
סגנון כתיבה מתייחס להרבה דברים, כמו למשל מיקום סוגריים מסולסלים {} בפונקציה, כמות הרווחים או טאבים (tabs) במעבר בין בלוקים של הקוד (indentation), שמות המשתנים והפונקציות ועוד הרבה דברים אחרים.
לא אוכל לכסות את הכל במאמר זה, כך שאתרכז בעיקר בשמות הפונקציות והמשתנים, ואולי אוסיף עוד כמה טיפים על דברים נוספים.
הסגנון לא חקוק בסלע. לרוב, כל חברה או קבוצת עבודה יקבעו את הסגנון משלה, בהתאם למי שהתחיל את הפרוייקט, או לאחר הבנה שצורה אחת עדיפה על השניה. כבר קרה לי שהסגנון השתנה באמצע פרוייקט גדול כשעבדתי בחברה גדולה ומכובדת, כדי להתאים אותו לכלים חדשים שהתחילו להשתמש בהם בפיתוח.
שמות המשתנים והפונקציות
כאמור, יש כמה צורות שאפשר להשתמש להגדרת משתנה או פונקציה. לצורות אלה יש אפילו כינוי מוסכם בקהילת המפתחים, הנה כמה מהם.
לצורך הדגמה בדרך כלל משתמשים ב-2 מילים רצופות. אשתמש ב-"Hello world" כשתי המילים כדי להדגים את הסגנון:
- lowercase/flatcase - צורה בה הכל כתוב באותיות קטנות -
helloworld - UPPERFACE - צורה בה הכל כתוב באותיות גדולות -
HELLOWORLD - PascalCase - צורה בה כל מילה מתחילה באות גדולה וממשיכה עם אותיות קטנות -
HelloWorld - camelCase - צורה בה המילה הראשונה מתחילה באות קטנה, כל מילה הבאה מתחילה באות גדולה וכל השאר נכתב באותיות קטנות -
helloWorld - snake_case - צורה בה הכל נכתב באותיות קטנות, אבל כל המילים מופרדות בקו תחתון -
hello_world - ALL_CAPS - צורה בה הכל נכתב באותיות גדולות, אבל כל המילים מופרדות בקו תחתון -
HELLO_WORLD
מכיוון שאין חוקים קבועים לצורת הכתיבה, אדגיש שוב, שתצטרכו להתרגל לצורה בה קבוצה קבעה לכתוב. חשוב מאוד שכל המפתחים בקבוצה יבינו אחד את השני לא רק בשיחה, אלא יוכלו להבין גם את מה שמפתח אחר כתב. אם אתם מצטרפים לקבוצה שכבר מפתחת משהו, אולי כדאי אפילו לשאול אם יש הנחיות סגנון כדי שהעבודה שלכם לא תראה מוזר.
אספר על הסגנון שאני התרגלתי לכתוב בו. לרוב הסגנון שלי מושפע מ-MFC של Microsoft.
לפונקציות ושמות המחלקות (Classes) אני רגיל להשתמש ב-PascalCase, כלומר כל מילה מתחילה באות גדולה - ThisIsMyFunction.
למשתנים אני רגיל להשתמש ב-camelCase, כלומר מילה ראשונה מתחילה באות קטנה, כל השאר באות גדולה - thisIsMyVariable.
קבועים, כלומר define#, אני רגיל לכתוב ב-ALL_CAPS, כלומר הכל באותיות גדולות עם קו תחתון בין המילים - MY_CONSTANT.
אלה שלושת הסגנונות הקבועים שלי. אבל יש עוד דברים שלפעמים מעלים שאלה גם אצלי בראש. למשל, אם יש משתנה קבוע, כלומר const int בתוך מחלקה, האם להשתמש ב-camelCase או ALL_CAPS? הוא גם משתנה וגם קבוע...
אז אני בדרך כלל מגדיר גם אותם ב-camelCase. הקומפיילר ידאג להזכיר לי שאי אפשר לשנות משתנים כאלה אם אנסה.
לקבועים מצטרפים גם Macros, שגם הם define#, אבל של פונקציה. אותם אני רגיל לכתוב באותה הצורה כמו ה-define# של קבועים, כלומר כ-ALL_CAPS.
זה לא הכל... יש גם צורת כתיבה הנקראת צורה הונגרית (Hungarian notation), בה מצרפים תווים וסימנים שיבהירו לכם במבט חטוף את סוג המשתנה ולרוב גם איפה הוא מוגדר. למשל:
- מוסיפים _m לפני כל משתנה בתוך מחלקה כדי לציין שהוא Class member
- מוסיפים g לפני משתנים גלובליים (כאלה שמוגדרים מחוץ למחלקות, אם אתם כותבים ב-C++)
- מוסיפים אותיות המגדירות את סוג המשתנה:
- b ל-
byte - c ל-
char - i ל-
int - l ל-
long - f ל-
float - sz - למחרוזת שמסתיימת ב-
NULL, כלומר Zero terminates string - s להגדרה של
struct - e להגדרה של
enum
- תוספת של שני קווים תחתונים
__לפני המשתנה או שם הפונקציה כדי להבהיר שזה משהו פנימי שלא לשימוש. לפעמים משתמשים בקו תחתון אחד לפני או אחרי השם כדי לציין שהמשתנה או הפונקציה היא private. סימונים אלה כנראה הגיעו ל-C/C++ משפות אחרות כמו Python ו-PHP, בהן יש משמעות מוגדרת לשימוש בקווים תחתונים.
כל זה מייצר שמות משתנים ארוכים ומוזרים, כמו gszName, או m_iCount.
אני אישית לא אוהב את צורת הכתיבה הזו ובפרוייקטים שלי לא משתמש בסגנון ההונגרי. במיוחד היום, שכל סביבת פיתוח שמכבדת את עצמה מראה מיידית את ההגדרה של המשתנה או הפונקציה עם מעבר של עכבר עליה, אפילו בלי שצריך להקליק משהו. בתקופה שקדמה לסביבות פיתוח כאלה כנראה שזה היה מועיל. היום זה רק מוסיף עוד תווים שצריך להקליד כדי שהמשלים האוטומטי (auto-completion) של סביבת הפיתוח יבין למה אנחנו מתכוונים. קווים תחתונים מעצבנים במיוחד, מכיוון שצריך ללחוץ על שני מקשים כדי לכתוב אותם (Shift ומינוס).
אולי אם כותבים את כל הקוד ב-C++ ומשתנה גלובלי זה משהו יחסית חריג, הייתי מוסיף את ה-g בהתחלה של השם כדי לציין זאת.
חוץ מתוספות אלה לשמות, יש גם תוספות שגם היום יש להם משמעות ורצוי להוסיף, במיוחד כדי לחלק את הקוד למודולים לוגיים. על חלוקה נכונה יהיה מדריך נפרד (TODO), אבל לגבי התוספות אסביר בהמשך.
שמות משמעותיים
זה נושא שהרבה מתכנתים מתחילים נופלים בו. ראיתי קוד עם שמות הפונקציות כמו ()foo ו-()bar כי ככה הן הועתקו מאיזה שהוא מדריך ונשארו בקוד.
תנו למשתנים ופונקציות שמות עם משמעות לתפקיד שלהם.
אם פוקציה מדליקה לד, אז תקראו לה בסגנון של ()LedOn או ()TurnLedOn ולא ()func1 או משהו שלא קשור לפעולה שהיא מבצעת.
אם משתנה מיועד לספור את כמות הלקוחות, תקראו לו numberOfCustomers או אם אתם ממש רוצים לקצר, אז אולי numOfCustomers או custNum - שזה כבר למתוח יותר מדי את הגבול לכיוון הפחות טוב. מה שבטוח שהשם לא צריך להיות num או cust ובטח שלא aa או משהו לא קשור.
עם סביבות הפיתוח המודרניות אתם מקלידים את השם המלא כנראה רק פעם אחת בהגדרה של המשתנה או הפונקציה. אחרי זה הקלדה של 2-3 אותיות הראשונות תספיק כדי שמנגנון השלמה אוטומטי יציע לכם את השם המלא המדוייק.
וכדי שהמשלים יעשה עבודה טובה יותר, במקרים שזה מתאפשר ולא שובר את ההגיון של השם, רצוי שהמילה הראשונה תהיה המשמעותית והמבדילה אותו מההאחרים. למשל, אם יש לכם כמה משתנים שמגדירים את מצב הלדים בצבעים שונים, יהיה יעיל יותר מבחינה הזו שהשמות יתחילו בצבע, כמו redLed ו-greenLed, מאשר שמות כמו ledGreen ו-ledRed. בצורה השניה תצטרכו להקליד יותר תווים כדי שהמשלים האוטומטי יגיע לתוצאה הנכונה.
ברוב המקרים אני בעצמי אשתמש בצורה הפחות אופטימלית של השמות כי אני אוהב יותר את האחידות של ההגדרות ופחות מוטרד מאורך ההקלדה. במיוחד כשיש יותר משני משתנים שקרובים במשמעות, כמו צבעים שונים של הלדים, או מספור של משהו, אז אני מעדיף קבוצות לוגיות בשמות, כמו למשל:
- קוד: בחר הכל
byte ledRed; byte ledGreen; byte ledBlue; int numberOfCustomers; int numberOfLogins; int numberOfOrders;
יש מקרים בהם לא רצוי להפוך את המילים, כמו למשל במקרה של firstName ו-lastName. לא הייתי משנה את הסדר שלהם, כי זה כבר לא ישמע הגיוני.
כמו שאומרים, לכל כלל תמיד יש יוצא מהכלל. כך גם בתחום הזה. רוב האנשים יסכימו ששימוש במשתנים כמו i ו-j זה משהו לגמרי מקובל בלולאות. גם אני מסכים עם זה, במיוחד אם מדובר על לולאות פשוטות, כשזה ברור כשמש שהמשתנה i משמש כ-index במערך. אבל לפעמים רצוי להשקיע קצת יותר ולתת גם למשתנים אלה שמות משמעותיים יותר. למשל, אם אתם עוברים על מבנה נתונים שבו יש מערך של הזמנות, ובו יש מערך של מוצרים לכל הזמנה, אז רצוי מאוד שמשתנים של הלולאה יקבלו שם כמו orderIndex או אפילו orderIdx מאשר רק i, וגם itemIndex מאשר רק j. בסופו של דבר הקוד בו מופיעים משתנים אלה יהיה הרבה יותר קריא.
רצוי גם לבחור שמות שלא ייצרו כפילויות. למשל, אם יש לכם מחלקה (class) שמייצג לד, אז בשונה למה שכתבתי קודם, השם שהייתי נותן לפונקציה שמדליקה את הלד הוא ()On או ()TurnOn. בצורה זו, הקוד להפעלת הלד על משתנה מסוג המחלקה הזו יראה הרבה יותר קריא בתור:
- קוד: בחר הכל
StatusLed blueLed; blueLed.On();
ולא
- קוד: בחר הכל
blueLed.LedOn();
חלוקה לוגית
נניח שאתם כותבים ספריה להפעלת מודול עם לד. יש לה פונקציות להפעלה וכיבוי, נניח ()LedOn ו-()LedOff וגם פונקציית אתחול ()Init. נניח גם שהקוד הוא ב-C ולא ב-C++.
נניח גם שאתם משתמשים בספריה אחרת, שמפעילה מנוע סרוו. גם לה יש כל מני פונקציות להפעלת המנוע וגם פונקציית ()Init.
במצב כזה הלינקר יצעק שיש מימוש כפול של פונקציית ()Init, כי הוא לא מבין שאלה פונקציות של ספריות שונות, שכנראה גם נמצאות בקבצים שונים. כשהוא מנסה לחבר את כל התוצרים שהוכנו ע"י הקומפיילר, הוא רואה שתי ישויות של ()Init ולא יודע מה לעשות איתן.
אז נחזור לתוספות לשמות הפונקציות... זה לא הגישה ההונגרית, זו הגישה הלוגית. חשוב לתת זיהוי לוגי לפונקציות שלכם. אם מדובר על ספריה של מודול לד, אז אולי כדאי שכל הפונקציות של אותה הספריה יתחילו ב-_Led ופונקציות של ספריית מנוע סרוו ב-_ServoMotor או אם זה ארוך מדי, אז אולי _SM או משהו בסגנון.
כל זה עדיין לא מבטיח שלא תהיה התנגשות. אם אתם משתמשים בספריה של שימעון משה, שהחליט גם הוא להוסיף _SM כמזהה של הפונקציות בקוד שלו, אז יכול להיות ששוב תהיה התנגשות.
בארדואינו הספריות ורוב הקוד כתוב ב-C++, כך שהפונקציות "מוחבאות" בתוך מחלקות (Classes), לכן צריך לדאוג לתת למחלקות שלכם שמות עם מזהה ברור. הפונקציות עם שמות שהרבה פעמים חוזרים על עצמם, כמו ה-()Init בדוגמה הקודמת, יהיו מוחבאים בתוך ההגדרה של המחלקה.
המזהה יכול להיות קשור לנושא שהקוד מטפל בו, לשם הפרוייקט, שם החברה או דברים נוספים.
למשל המחלקות בספריות של Adafruit מתחילות ב-_Adafruit. מחלקות בספריות של SparkFun לרוב מתחילות ב-_SFE או Qwiic, שזה השם שהם נתנו לחיבור בין הרכיבים שהם משתמשים בו כמעט לכל מוצר חדש שהם מוציאים.
בפרוייקטים האחרונים שלי נתתי קידומת לפי שם הפרוייקט. שמות כל המחלקות בספריית ה-Event Based Framework מתחילים ב-_EBF. שמות כל המחלקות בספריית ה-Plug-n-Play שאני עובד עליה בימים אלה מתחילים ב-_PnP.
וכן, יש את ה-namespace בשפה הרשמית (קישור ל-wiki), שמוסיף עוד שכבה של הגנה מפני כפילויות. אבל נדיר שמישהו משתמש בזה ב-C/C++. רפרפתי בקוד של Adafruit ב-GitHub שלהם, לא ראיתי שהם משתמשים ב-namespace בספריות שלהם. גם לא SparkFun, חוץ ממקרה אחד שהם כנראה הסתבכו עם השמות של הקוד שהם עצמם כתבו. יש קצת שימוש בקוד של Arduino, אבל זה לא היה נראה לי כמו משהו נרחב. לספריות שמתווספות לפרוייקטים יהיה כנראה יותר סיכוי להתנגשות בשמות מאשר קוד הבסיס של ארדואינו.
כלים לשמירה על הסדר
חוץ מלקבוע את סגנון הכתיבה, הרבה חברות גם אוכפות אותו ע"י כלים שונים שבודקים שהמפתחים לא חורגים מהכללים שנקבעו. יש לא מעט כלים כאלה, אבל כולם עושים Linting. זה מושג שנלקח מכלי לינוקסי בשם lint שעשה בדיוק את מה שתיארתי במאמר זה, בדק את הקוד לפני הקומפילציה.
עם הזמן הקומפיילרים לקחו על עצמם יותר ויותר בדיקות שבעבר רק כלי ה-lint היו מזהים.
לדוגמה, אם תכתבו סימן שווה אחד = בשורת בדיקת תנאי בתוך ה-if, רוב הקומפיילרים המודרניים יתריעו על כך, לפחות כ-warning. בעבר הרחוק יותר הקוד היה יכול להתקמפל ללא שום התרעה.
לכלים אלה אפשר להגדיר את כל החוקיות של סגנון הכתיבה שהזכרתי קודם, כך שהקומפילציה שלכם תכשל אם אתם חורגים מהכללים.
אם אתם עובדים ב-VSCode, אז תוכלו להתקין כמה תוספים (extensions) לסביבת העבודה שיבדקו ויסדרו את הקוד שלכם לפי ההגדרות שתקבעו.
יש כלים שיסמנו לכם איפה אתם חורגים מהכללים ויש כאלה שרק יסדרו לכם את הקוד אם תבקשו. לקוד C/C++ אני משתמש בתוסף בשם "Clang-Format" ונעזר בו כשצריך לסדר קוד מבולגן כלשהו. בקוד PHP אני משתמש בתוסף "phpcs" שהוא קצת יותר מקפיד ומכריח אותי לכתוב בצורה אחידה.
אם אתם משתתפים באיזה שהוא פרוייקט גדול ב-GitHub, יכול להיות שכבר נתקלתם במנגנונים שבודקים את הקוד של ה-PR שלכם ולפעמים גם דוחים את ה-PR אם משהו לא עבר בדיקות שבעלי הפרוייקט קבעו. לרוב אלה בדיקות פשוטות יחסית, כמו מבנה הספריות ושיהיו כל הקבצים הדרושים, אבל הם יכולים להוסיף גם בדיקות שקשורות לסגנון הכתיבה כדי שרק הקוד שעומד בסטנדרטים שלהם יוכל להתקבל לפרוייקט.
טיפים
בלי קשר לשמות הפונקציות והמשתנים, חשוב להקפיד על קוד קריא וברור לכולם.
אחד הנושאים שמשפיעים על הקריאות זה indentation אחיד. כלומר כמות הרווחים או טאבים (tabs) בין רמות קוד שונות.
כשבלוק אחד מוזז 2 רווחים ובלוק אחר 4 רווחים - זה מקשה על העיניים כשאתם רוצים לעבור על הקוד במהירות. למשל:
- קוד: בחר הכל
void Init(int param) { int code; if (param == 0) { code = 1; } }
זו אומנם דוגמה קצרה ופשוטה ויכול להיות שלא מבהירה לעומק את הבעיה. אבל כשהקוד קצת יותר מסובך וכולל כמה רמות בלוקים אחד בתוך השני, בלי שהרווחים או הטאבים יהיו מסודרים ואחידים, יהיה קשה מאוד לעקוב אחרי ההגיון של הקוד. הרווחים לא משפיעים על הקומפילציה, אלא רק על הנוחות שלנו לקרוא את הקוד.
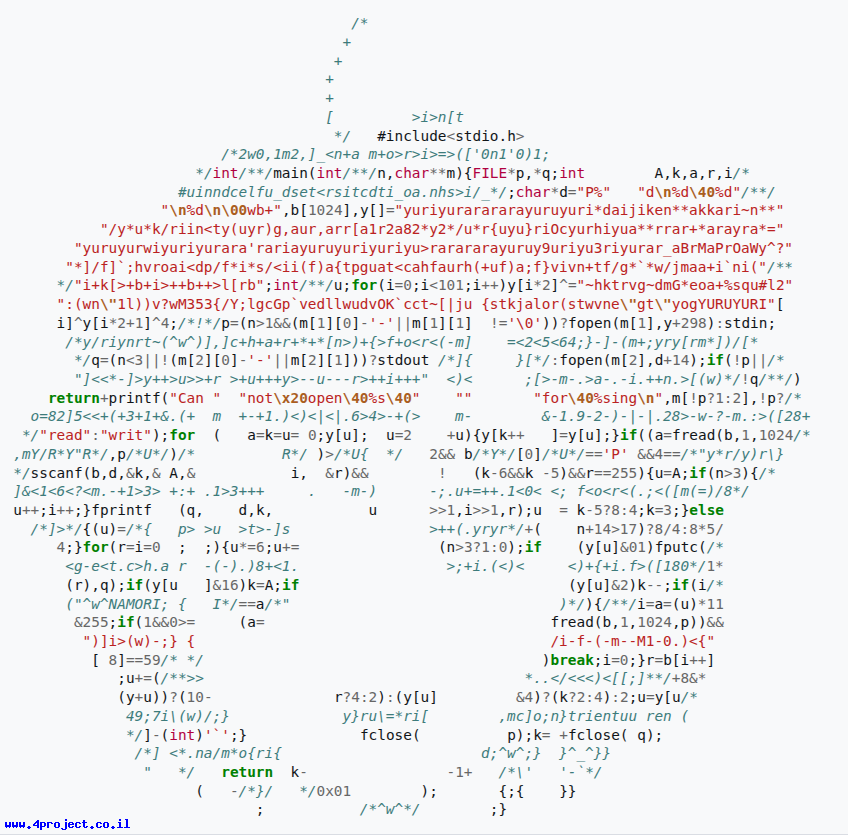
בסופו של דבר אנחנו לא בתחרות IOCCC שמבקש מאנשים לשלוח קוד הכי מוזר שהם יכלו לייצר בשפת C, שעדיין עובד.
הנה דוגמה אחת מ-wikipedia על הנושא הזה:
קצת באותו הקשר, יש ויכוח עתיק לגבי איפה לשים את סוגר הפתיחה בפונקציות ובלוקים לוגיים בתוך הפונקציה. כלומר, האם זה צריך להיות כך:
- קוד: בחר הכל
void Init(int param) {
או כך:
- קוד: בחר הכל
void Init(int param) {
גישת הסוגר בשורה הבאה אומרת שיהיה יותר קל לזהות את התחילה והסוף של הבלוק, כי הסוגרים יהיו באותה רמת ה-indentation על המסך, כך שברפרוף של הקוד יהיה קל לזהות את זה בעיניים.
הגישה של הסוגר באותה השורה אומרת שזה חוסך את כמות השורות, כך שקוד קצר יותר יהיה קל יותר להבנה. במיוחד כשיש הרבה IFs קצרים בקוד.
לי אין דעה מוצקה לסוגיה זו. אני רגיל לשים סוגר בשורה חדשה אחרי שם הפונקציה, כי זה מדגיש קצת יותר את ההגדרה של הפונקציה משאר הקוד, ולפעמים הפונקציות יכולות להיות קצת ארוכות, כך שזה יכול להקל על קישור בין ההתחלה והסוף שלה בקוד.
לבלוקים לוגיים (IF, לולאות וכו') אני לרוב שם את סוגר הפתיחה באותה השורה, כי הבלוקים אמורים להיות קצרים. התוסף CLang ב-VSCode מקפיד להוריד את הסוגר לשורה חדשה אם אני עושה Format לקוד בעזרתו. ואם הבלוקים הלוגיים ארוכים מדי - זה סימן לכך שכנראה שצריך לחלק את כל הקוד לפונקציות נוספות.
את הקוד של הדוגמה הקודמת אפשר לרשום גם בלי הסוגריים המסולסלים ב-IF:
- קוד: בחר הכל
if (param == 0) code = 1;
לסגנון זה דווקא יש לי דעה מוצקה ואני ממליץ לא להשתמש בצורת כתיבה זו מכמה סיבות.
סיבה ראשונה זה שוב ה-indentation. אם באותה הפונקציה יש IFs עם סוגריים מסולסלים, זה אומר שחלק מהקוד יהיה ב-indent אחד וחלק אחר הרבה יותר ימינה על המסך, וזה מקשה על המעבר המהיר על הקוד.
סיבה שניה היא שעם הזמן למדתי שהרבה פעמים אני צריך להוסיף משהו לתוך הקוד של ה-IF, כמו למשל במקרה של עבודה עם ארדואינו הרבה פעמים מוסיפים הדפסה בכל מני מקומות בקוד כדי לעשות debug. במקרה כזה אני מוצא את עצמי "מעצב" את הקוד ומוסיף את הסוגריים המסולסלים כדי שאפשר יהיה להוסיף עוד שורת קוד לתוך ה-IF.
ומה לעשות עם הסוגריים האלה אחרי שאני כבר לא צריך את ההדפסה? להוריד אותן? להשאיר?
אחרי כמה מקרים כאלה החלטתי שעדיף תמיד להוסיף את הסוגריים לכל הבלוקים ולא לחשוב על זה יותר. כשכותבים את הקוד במהירות, זה קורה לבד, סוג של הרגל.
מדריכים נוספים בסדרת כותבים קוד יותר טוב:
- תיעוד
- גיבוי וניהול גרסאות
- מספרי קסם
- חלוקה של הקוד (TODO)
- הקצאה דינמית של זיכרון (TODO)
- מכונות מצבים (TODO)
יש לכם הערות או שאלות?
מוזמנים לשאול ולהגיב כתגובה לפוסט זה בפייסבוק.